
티스토리 뷰
목차
서비스 배경
필요 기술
1️⃣ OCR
1. 도메인 생성하기
2. API Gateway 신청하기
3. API 연동하기
4. API 사용하기
2️⃣ KoSentenceBERT
1. Ubuntu 설치하기
2. Ubuntu 사용하기
3. Anaconda 설치하기
4. KoSentenceBERT 설치하기
5. KoSentenceBERT 사용하기
서비스 배경
시간이 흘러 졸업 프로젝트 하는 날이 다가왔습니다. 저희 팀이 선정한 서비스는 '판례 암기 어플'인데요. 저희의 주요 타겟은 변리사 시험을 준비하는 고시생입니다.
변리사 시험은 1차와 2차로 진행되는데, 서술형 형식의 2차 시험에서는 답안에 판례 내용을 문장 그대로 적는 실력이 요구된다고 합니다. 그럼 답안에 적는 '판결 요지' 하나가 얼마나 길냐 하면, '연차수당지급' 판례에 적힌 판결 요지 하나를 가져왔습니다.
근로기준법에 따르면, 사용자는 1년간 80% 이상 출근한 근로자에게 15일의 연차휴가를 주어야 하고(제60조 제1항), 계속하여 근로한 기간이 1년 미만인 근로자 또는 1년간 80% 미만 출근한 근로자에게도 1개월 개근 시 1일의 유급휴가를 주어야 한다(제60조 제2항). 연차휴가를 사용할 권리 또는 연차휴가수당 청구권은 근로자가 전년도에 출근율을 충족하면서 근로를 제공하면 당연히 발생하는 것으로서, 연차휴가를 사용할 해당 연도가 아니라 전년도 1년간의 근로에 대한 대가에 해당하므로, 다른 특별한 정함이 없는 한 전년도 1년간의 근로를 마친 다음 날 발생한다. 결국 근로기준법 제60조 제1항은 최초 1년간 80% 이상 출근한 근로자가 그다음 해에도 근로관계를 유지하는 것을 전제로 하여 2년 차에 15일의 유급휴가를 부여하는 것이어서, 1년 기간제 근로계약을 체결하여 1년의 근로계약기간이 만료됨과 동시에 근로계약관계가 더 이상 유지되지 아니하는 근로자에게는 근로기준법 제60조 제2항에 따라 최대 11일의 연차휴가만 부여될 수 있을 뿐 근로기준법 제60조 제1항에서 정한 15일의 연차휴가가 부여될 수는 없다. 그러나 1년을 초과하되 2년 이하의 기간 동안 근로를 제공한 근로자에 대하여는 최초 1년 동안의 근로제공에 관하여 근로기준법 제60조 제2항에 따른 11일의 연차휴가가 발생하고, 최초 1년의 근로를 마친 다음 날에 근로기준법 제60조 제1항에 따른 15일의 연차휴가까지 발생함으로써 최대 연차휴가일수는 총 26일이 된다.
운이 좋게도 저희 팀 멘토가 변리사셔서, 그분에게 조언을 구한 결과, 대부분의 고시생은 1) 학원에서 암기에 필요한 프린트물을 받는다는 것, 2) 판례 내용을 말하거나 써보면서 자신이 완벽히 암기했는지 확인해본다는 거였습니다.
필요 기술
저렇게 긴 판결 요지를 어플에 직접 작성한다는 건 정말 비효율적이고, 사용자가 작성한 긴 문장을 정답과 비교해야 되기 때문에, 저희는 크게 두 가지 기술을 사용하기로 했습니다.
1️⃣ OCR 이미지에서 텍스트 추출하기
고시생이 미리 받은 프린트물의 판례 내용을 쉽게 어플에 저장할 수 있도록 OCR 기술을 적용하여 사진에서 텍스트를 추출하고자 합니다.
어떤 OCR API를 사용할까 둘러보던 중, 아무래도 한국어가 잘 지원되는 국내 API를 선택했습니다. 그중 요즘 3개월 동안 사용 가능한 10만원 크레딧을 주는 네이버 CLOVA OCR을 먼저 살펴봤습니다.
NAVER CLOUD PLATFORM
cloud computing services for corporations, IaaS, PaaS, SaaS, with Global region and Security Technology Certification
www.ncloud.com
네이버 클라우드 플랫폼 서비스를 사용하려면 우선 로그인을 해야 합니다. 네이버 아이디로 쉽게 로그인 할 수 있습니다.
이벤트 중인 10만원 크레딧은 그냥 받을 수 있는 게 아니라, 본인 카드를 먼저 결제 수단으로 등록하면 신청하여 받을 수 있습니다. 이벤트는 아래 이미지처럼 '네이버 클라우드 플랫폼 할인 크레딧 제공'에서 확인하세요.
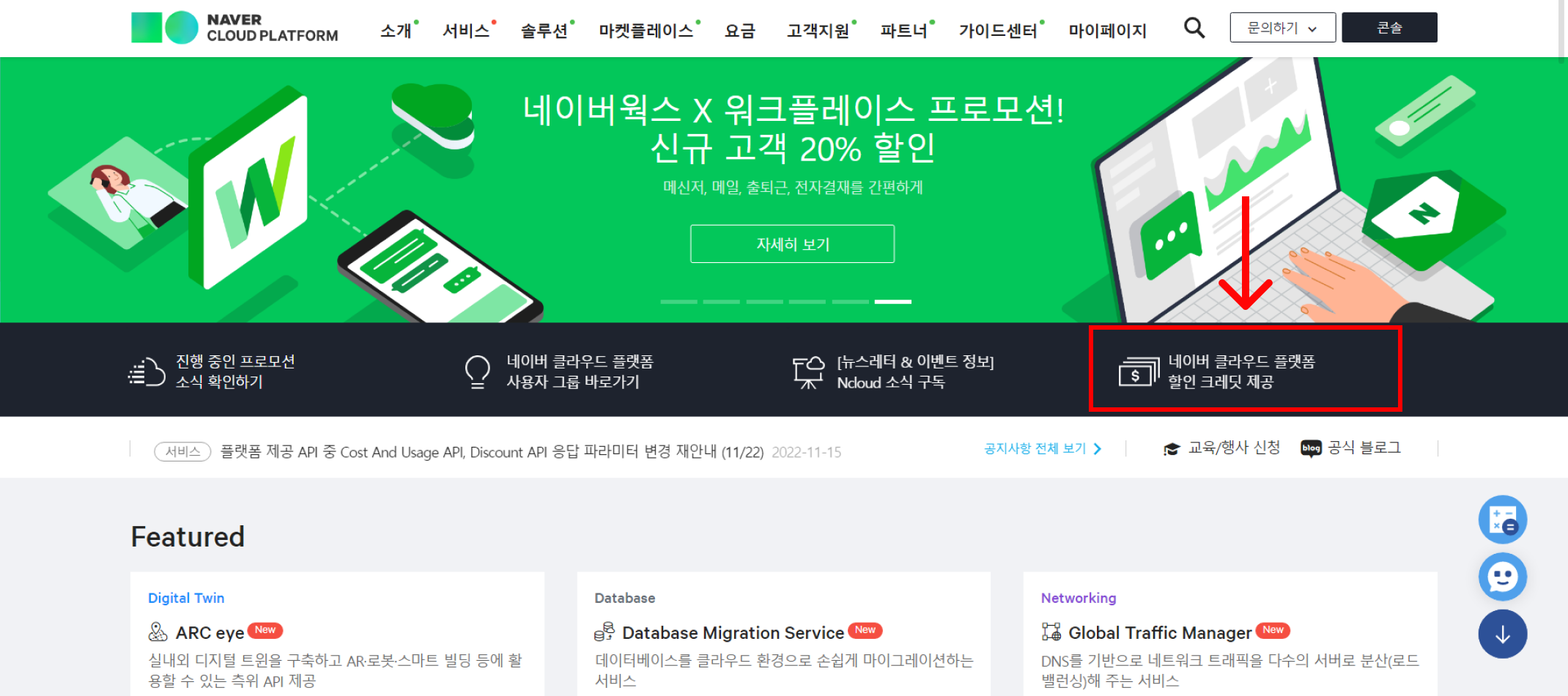
이제 CLOVA OCR 사용 방법을 알아봅시다. 과정은 사용 가이드를 참고했어요. 먼저 OCR 서비스에서 '이용 신청하기'를 눌러주세요. 신청이 완료되면 자신의 Dashboard(콘솔)에 OCR이 생깁니다.
1. 도메인 생성하기
Domain 메뉴에서 '도메인 생성'을 눌러주세요.

인식 모델은 General, Template, Document 총 3개가 있는데요. 판결 요지를 추출하는 저희는 강사 별로 프린트물 형식도 다양하기 때문에 굳이 템플릿(증명서처럼 고정 폼이 있는 문서)을 사용할 필요가 없습니다. 그래서 General로 진행하겠습니다.

2. API Gateway 신청하기
이제 생성된 도메인에서 Secret Key와 Invoke URL을 생성해야 하는데, 그러려면 API Gateway를 먼저 신청해야 합니다. 여기에서 신청 가능합니다. 정말 '이용 신청'만 해주시면 됩니다.
3. API 연동하기
생성한 도메인에서 'Text OCR'을 눌러주세요.

Secret Key에서 '생성', APIGW 자동 연동에서 '자동 연동'을 클릭하면, 다음과 같이 Secret key 와 Invoke URL이 생성됩니다. 이 값을 메모해주세요.

4. API 사용하기
CLOVA OCR Custom API 문서를 참고했습니다. Postman에서 테스트 해보겠습니다. (Postman을 사용하려면 로그인이 필요합니다)
- 자신의 Workspace에서 New > HTTP Request를 선택합니다.

- 요청 방식을 POST로 설정하고
- 아까 메모해둔 inovke URL을 입력합니다.
- 그 다음 Headers에 아래 사진처럼 Content-Type과 X-OCR-SECRET(OCR에서 받은 Secret Key)을 설정합니다.

- 이제 Body 탭에서 요청을 보내봅시다.
- raw를 선택하고 파일 방식을 JSON으로 선택합니다.
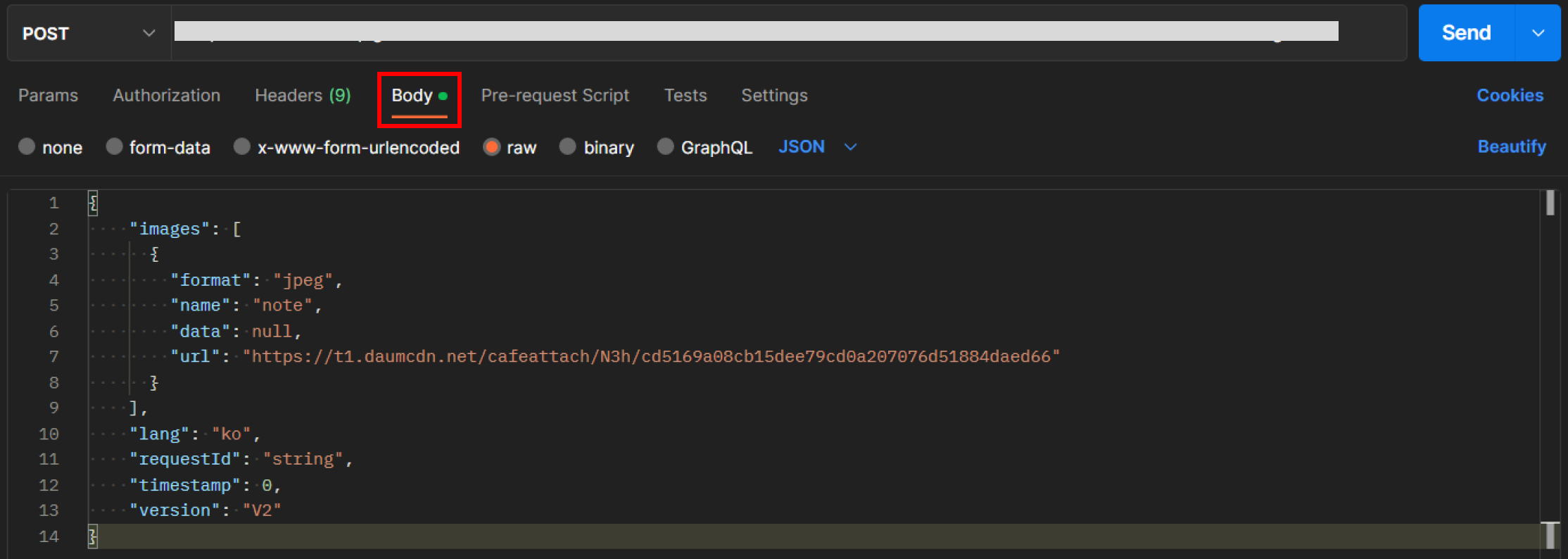
// 요청 응답 JSON
{
"images": [ // 이미지 정보
{
"format": "jpeg",
"name": "note",
"data": null,
"url": "image URL" // 텍스트 추출에 사용할 이미지 주소
}
],
"lang": "ko", // 언어
"requestId": "string",
"timestamp": 0,
"version": "V2" // V1과 V2가 있는데, V2는 boundingPoly 정보를 제공
}위 코드처럼 Body에 요청 JSON를 입력하고 Send를 눌러 요청을 보내면 응답이 옵니다. 응답을 성공적으로 받으면, 저희가 필요로 하는 텍스트 정보는 images.fields에 들어있습니다.
// fields 값 중 하나 예시
{
"valueType": "ALL",
"boundingPoly": {
"vertices": [...]
},
"inferText": "효력", // 추출한 텍스트
"inferConfidence": 1.0,
"type": "NORMAL",
"lineBreak": false // 줄 바꿈을 알 수 있는 boolean 값 (True이면 해당 텍스트 다음에 줄이 바뀜)
},Naver CLOVA OCR API가 잘 작동하는 걸 확인했습니다! 어플에서는 사용자가 사진을 촬영하거나 앨범에서 사진을 선택하면 텍스트를 추출하여 보여줄 예정입니다.
2️⃣ BERT 문장 간 유사도 구하기
두 번째로, 사용자가 판례를 서술하면 원문과 얼마나 일치하는지 보여주기 위해 BERT를 사용해봅시다. 멘토님의 도움을 받아 한글도 지원이 되는 KoSentenceBERT를 Github에서 찾았습니다. 리드미에 나와있는 데로 개발 환경을 만들어야 하는데, 팀원끼리 수없이 시도한 결과 어느 정도의 운이 따라주길 빌어야 할 것 같네요😭
저는 Windows에 설치를 하려고 했으나 계속 에러가 나서 Ubuntu로 실행하여 성공했습니다. 그 과정을 공유할게요.
1. Ubuntu 설치하기
친절하게도 Microsoft에서도 WSL 설치 방법을 안내하고 있습니다. wsl을 설치하면 Windows 컴퓨터에서 Windows와 Linux를 모두 사용할 수 있습니다. (Ubuntu를 설치한지 오래돼서, 이 글보다 되도록 문서를 참고하는 게 건강한 방법입니다..)
- Windows PowerShell을 실행하여 다음 명령어를 실행합니다.
wsl --install문서에 따르면 기본적으로 버전은 wsl2로 설정되고, Linux 배포판은 Ubuntu로 설치된다고 합니다.
- 혹시 버전이 wsl1이라면 여기를 참고하여 wsl2로 업데이트 하세요.
- Ubuntu가 설치되어 있지 않다면, 여기서 설치해주세요. (더 높은 버전도 있으나, 저는 18 버전을 사용 중입니다)
2. Ubuntu 사용하기
설치한 Ubuntu를 실행하면 윈도우 계정처럼, 사용자 이름과 암호를 입력하여 Linux 배포 계정을 생성합니다. 비밀번호를 입력할 때는 아무것도 안 뜨는 게 정상이니 잘 입력하면 됩니다.
이제 WSL을 통해 Ubuntu 등 설치한 Linux 배포판을 사용해봅시다. 문서에서는 Windows 터미널을 설치하길 권장하고 있는데, 윈도우 터미널을 사용하면 여러 명령 줄 도구 및 셸을 쉽게 사용할 수 있습니다. 여기에서 설치 해주세요.
윈도우 터미널을 깔고 실행해보면 다음 이미지처럼 Ubuntu를 사용할 수 있습니다. 저는 윈도우에 설치한 Ubuntu와 wsl로 설정한 Ubuntu가 둘 다 있는데, 아마 따로 Ubuntu를 설치해서 그런 것 같습니다. 둘 중 하나로 사용하시면 됩니다.

3. Anaconda 설치하기
BERT 같이 자연어 처리 환경을 만들려면 Python부터 무수히 많은 패키지를 설치해야 합니다. 하지만 이런 걸 한 번에 다운로드할 수 있는데, 바로 Anaconda를 설치하면 됩니다.
Linux 환경에서 사용할 거니까 아까 설치한 Ubuntu를 통해 다운받아야 합니다. Python 3.9 버전을 가진 Anaconda를 설치하겠습니다. Anaconda Old packages lists를 확인해보면 2021.11 Anaconda를 설치해야 합니다.

Anaconda 패키지가 있는 이 주소에서 자신이 깔고 싶은 버전을 찾아 오른쪽 키를 눌러 링크를 복사합니다. 이 링크를 가지고 적절한 곳에 파일을 설치하면 되는데, 저는 /opt 경로에 설치하겠습니다. 윈도우 터미널을 '관리자 권한'으로 실행하여 Ubuntu를 열고, 다음 명령어를 입력합니다.
# 원하는 위치로 이동
cd /opt
# 웹에서 파일 다운 받기
wget https://repo.anaconda.com/archive/Anaconda3-2021.11-Linux-x86_64.sh
# 다운 받은 파일 설치
sudo bash Anaconda3-2021.11-Linux-x86_64.sh
설치를 완료하면 Anaconda를 initialize 하여 사용할 수 있습니다. 아래 명령어를 입력하면 이제 conda 명령어를 사용할 수 있습니다.
source /opt/anaconda3/bin/activate
conda init
source ~/.bashrc
콘솔을 킬 때 자동으로 활성화하고 싶다면 다음 명령어로 설정하면 됩니다.
# conda 환경 자동 활성화
conda config --set auto_activate_base True
# conda 환경 자동 활성화 해제
conda config --set auto_activate_base False🐛Bug
NotWritableError: The current user does not have write permissions to a required path.
conda를 사용할 권한이 없어서 뜨는 에러 같습니다. 위 에러가 뜬다면 uid도 함께 표시되는데, 다음 명령어로 자신에게 권한을 부여합니다.
sudo chown -R $USER:$USER {anaconda3 폴더 경로}
# 예를 들어
sudo chown -R 1000:1000 /opt/anaconda34. KoSentenceBERT 설치하기
그럼 이제 아까 찾은 KoSentenceBERT를 사용해봅시다. github의 리드미 대로 우선 git clone을 해야 합니다. 저는 기본적으로 제 home 경로(~/)에 다운로드하겠습니다. 다음은 리드미에 있는 명령어에 설명만 약간 추가한 코드입니다.
# home 으로 이동
cd ~/
# KoBERT 클론
git clone https://github.com/SKTBrain/KoBERT.git
# KoBERT 폴더로 이동
cd KoBERT
# requirements에서 요구하는 버전으로 패키지 다운로드(업데이트)
pip install -r requirements.txt
pip install .
# 폴더 밖으로 나가기
cd ..
# KoSentenceBERT 클론
git clone https://github.com/BM-K/KoSentenceBERT_SKTBERT.git
# KoSentenceBERT 폴더로 이동
cd KoSentenceBERT_SKTBERT
# 마찬가지로 패키지 다운로드 (업데이트)
pip install -r requirements.txtpip은 ananconda를 설치할 때 자동으로 설치됩니다. 위 과정이 모두 순조롭게 진행되면 참 좋겠지만, 특히 requirements 대로 패키지를 다운로드(업데이트) 할 때 에러가 많이 납니다.
혹시 오류가 난다면 우선 깃허브의 issue에서 찾아보세요. 구글에 검색해도 좋지만 한국어 지원 BERT이다 보니 영어 기반인 BERT보다 정보가 부족하더라고요. 장점이자 단점입니다😅
5. KoSentenceBERT 사용하기
위 과정을 무사히 마쳤다면 이제 패키지를 이동해야 합니다. KoSentenceBERT를 열면 transformer, tokenizers, sentence_transformers 패키지가 있습니다. 이걸 anaconda의 패키지 폴더로 이동해야 합니다. 저 같은 경우엔 경로가 /opt/anaconda3/python3.9/site-packages 입니다.
콘솔 명령어로 멋지게 옮겨도 되고, 저는 code . 명령어를 통해 VScode를 실행하여 폴더를 손수 옮겼습니다. Linux에 있는 폴더를 Windows 탐색기로 볼 수 있는 명령어도 있는데, 어떤 방법을 써서든 저 3개의 폴더를 옮겨주세요. (저와 같은 방법으로 할 거면, 터미널을 관리자 권한 말고 그냥 실행해주세요. 관리자 권한이면 폴더를 드래그해서 이동하는 게 막힙니다.)
패키지를 이동했으면 이제 학습 파일을 다운받아 넣어줄 건데요. 저는 수많은 파일 중 SemanticSearch.py 로 문장 간 유사도를 구할 겁니다. Query 문장과 가장 유사한 문장 5개를 Corpus에서 가져와 점수를 보여줍니다.
코드를 보면 해당 파일은 STS 학습 방법을 사용했습니다. 공유된 구글 드라이브에 들어가서 sts 폴더에 있는 result.pt 파일을 다운로드합니다. 용량이 크니 좋은 와이파이를 사용하세요. 이 파일을 KoSentenceBERT 폴더에서 output/training_sts/0_Transformer/result.pt 처럼 넣어주세요. 0_Transformer 폴더는 직접 만드시면 됩니다. (지금 하는 김에 다른 학습 데이터도 다 넣어주셔도 돼요. 사용할 일이 있을 수도 있잖아요?)
이제 정말로 SemanticSearch.py를 실행해봅시다! VScode에 Python Extension Pack을 깔지 않았다면 설치해주세요.

SemanticSearch 파일을 열고 F5로 실행하면 되는데요. 혹시 이미 다른 Python을 설치해서 사용 중이었다면 Python Interpreter를 conda로 설정해야 합니다. Ctrl + Shift + P를 눌러 Python Interpreter을 검색하고 conda의 python을 선택해주세요.


이제 실행해보면 터미널에 다음과 같이 출력됩니다.
======================
Query: 한 남자가 파스타를 먹는다.
Top 5 most similar sentences in corpus:
한 남자가 음식을 먹는다. (Score: 0.6800)
한 남자가 빵 한 조각을 먹는다. (Score: 0.6735)
한 남자가 말을 탄다. (Score: 0.1256)
두 남자가 수레를 숲 솦으로 밀었다. (Score: 0.1077)
한 남자가 담으로 싸인 땅에서 백마를 타고 있다. (Score: 0.0968)
======================
Query: 고릴라 의상을 입은 누군가가 드럼을 연주하고 있다.
Top 5 most similar sentences in corpus:
원숭이 한 마리가 드럼을 연주한다. (Score: 0.6832)
한 여자가 바이올린을 연주한다. (Score: 0.2885)
치타 한 마리가 먹이 뒤에서 달리고 있다. (Score: 0.2278)
그 여자가 아이를 돌본다. (Score: 0.2018)
한 남자가 말을 탄다. (Score: 0.1397)
======================
Query: 치타가 들판을 가로 질러 먹이를 쫓는다.
Top 5 most similar sentences in corpus:
치타 한 마리가 먹이 뒤에서 달리고 있다. (Score: 0.8141)
두 남자가 수레를 숲 솦으로 밀었다. (Score: 0.3707)
원숭이 한 마리가 드럼을 연주한다. (Score: 0.1842)
한 남자가 말을 탄다. (Score: 0.1716)
한 남자가 담으로 싸인 땅에서 백마를 타고 있다. (Score: 0.1519)혹시 바로 실행되셨다면 축하드립니다. 높은 확률로 오류가 났다면, 이제 그 버그를 하나씩 잡아가면 됩니다. 이것도 issue 먼저 확인해보세요. 제가 마주친 버그는 여기에 공유하겠습니다.
🐛Bug
If you are running on a CPU-only machine, please use torch.load with map_location=torch.device('cpu') to map your storages to the CPU.
issue에도 같은 에러가 있습니다. 현재 코드는 GPU로 실행하도록 되어 있는데, 저처럼 따로 GPU를 설치하지 않았으면 CPU로 코드를 실행해야 합니다. anaconda3의 site-package/torch/serialization.py 파일을 수정합니다. 다음 코드를 찾아서 'gpu'를 'cpu'로 수정합니다.
# ~ site-package/torch/serialization.py
def load(f, map_location='cpu', pickle_module=pickle, **pickle_load_args):
[Error] RuntimeError: Error(s) in loading state_dict for BertModel: Missing key(s) in state_dict: ‘embeddings.position_ids’.
다른 블로그에서 해결 방법을 찾았습니다. 이 방법으로 코드를 수정하면 추후 문제가 발생할 수 있다고 하지만, 저는 SemanticSearch.py 파일만 사용할 거니까 우선 이대로 진행하겠습니다😂
anaconda3의 site-packages/sentence-transformers/models/Transformer.py 41번째 코드에 다음처럼 strict=False를 추가해주세요.
# ~ site-packages/sentence-transformers/models/Transformer.py
self.auto_model.load_state_dict(torch.load(model_name_or_path+'/result.pt'), strict=False)
여기까지 했더니 드디어 SemanticSearch.py 파일을 실행할 수 있었습니다! 새벽에 혼자 너무 기뻐서 만세를 외쳤어요. 어플에 사용할 때는 query와 corpus 문장에 판결 요지를 넣어서 나온 Score에 100을 곱해서 % 비율로 사용자에게 보여줄 예정입니다.
여기까지 판례 암기 어플을 만들기 위해 OCR과 KoSentenceBERT 기술을 검증해보는 과정이었습니다. 다음 글에서는 기술을 실제로 어플에 적용해서 보여드리겠습니다. 긴 글 읽어주셔서 감사합니다🙇
'💻 프로젝트' 카테고리의 다른 글
| [토킹 AI 책 친구] 초등학교 저학년 대상 동화 재창작 서비스 (0) | 2023.06.25 |
|---|---|
| [메멘토] 판례 암기 애플리케이션 - 프론트엔드 구현 (0) | 2023.05.12 |
| Mood Player - 기분 맞춤 노래 제공 서비스 | 모바일앱제작 개인 프로젝트 (0) | 2021.12.30 |
- Total
- Today
- Yesterday
- python
- 백준
- fetch
- 파이썬
- rn
- 코어자바스크립트
- node.js
- 코테
- nodeJS
- Spotify
- 코딩테스트
- DP
- javascript
- 다이나믹프로그래밍
- 문제풀이
- 백트래킹
- 프로그래머스
- React
- p5js
- flutter
- backtracking
- dfs
- 비동기
- 코드분석
- React.js
- Unsplash
- 알고리즘
- Python3
- 이벤트루프
- React-native
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |